拓扑排序
看这个部分的原因是什么呢?啊,我忘记了,可能是数据老师上课的时候讲过恰巧听见了?(完全没有听过课),也可能是看了一眼发现其实并不难,然后就总结一下吧。
当然我肯定不是自己靠意念学会的,主要就是看了CSDN的一篇文章,很不错,受益匪浅!在开始我自己的”复述”之前,就先把他的链接放下吧!拓扑排序入门(真的很简单)_安得广厦千万间的博客-CSDN博客_拓扑排序。实际上这位大神确实讲的很清楚了,我写的原因是为了温习自己所学,以后看自己的文字也更亲切一点吧!
什么是拓扑排序?
首先拓扑排序必须是在一个有向无环图(DAG)中,把入度为0的节点输出,直到所有的节点都输出,所输出的序列就是拓扑排序的序列。
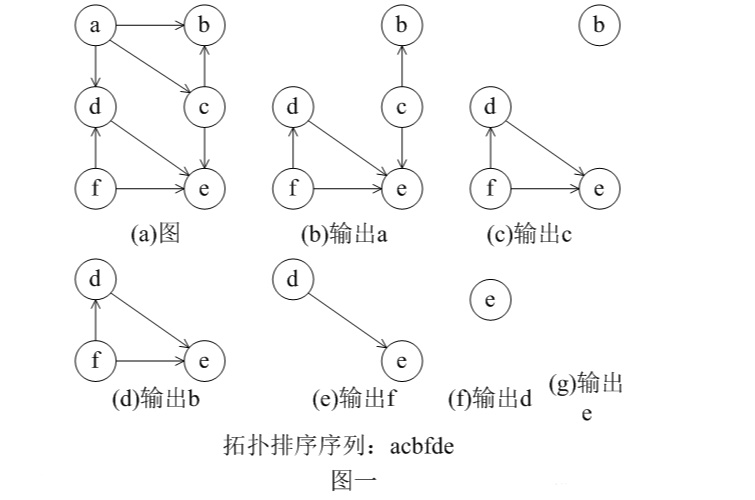
如上图所示,a的入度为0输出a,c的入度为0输出c ……最终得到的序列就是acbfde
当然,由于在同一时间可能有多个节点的入度为0,那么拓扑排序所得的序列就不是唯一的,而让他变成唯一的可能就是用到拓扑排序的题的精髓所在(如:字典序,倒序,数小优先 等等……)
如果看了以上的内容你还是懵懵懂懂,那么,举一个生活上的例子:小明是体育委员,他想给同学们按照身高来排队,他每次只能对比两个同学的身高,经过两个两个人的比较,最终就可以得到排好的队伍(由部分的对比来完成整体的对比)
拓扑排序的朴素写法
CODE:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| int a[N];
bool pos[N][N];
int main(){
int n,m,x,y,tmp;
cin>>n>>m;
for(int i=1;i<=m;i++) {
cin>>x>>y;
if(pos[x][y]==false) {
pos[x][y] = true;
a[y]++;
}
}
for(int i=1;i<=n;i++) {
for(int j=1;j<=n;j++) {
if(a[j]==0) {
cout<<j<<" ";
a[j]--;
tmp = j;
break;
}
}
for(int j=1;j<=n;j++)
if(pos[tmp][j])
a[j]--;
return 0;
}
|
解释:
很容易就能想到朴素写法,就是不断的遍历节点,直到所有节点都输出了(注意如果有重复输入的关系,可能需要加一点东西)。
朴素的写法的复杂度是O(n^2)。很容易看出来,确实好写,大多数情况感觉用不到。。
优化版的写法
CODE:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| queue<int> q;
vector<int> edge[n];
for(int i=1;i<=n;i++)
if(in[i]==0)
q.push(i);
vector<int> res;
while(!q.empty())
{
int tmp=q.front(); q.pop();
res.push_back(tmp);
for(int i=0;i<edge[tmp].size();i++)
{
int x=edge[p][i];
in[x]--;
if(in[x]==0)
q.push(x);
}
}
if(res.size()==n)
{
for(int i=0;i<res.size();i++)
printf( "%d ",res[i] );
printf("\n");
}
else printf("No Answer!\n");
|
解释:
这样的复杂度是O(n+m)点和边的和,太好了吧!!这样就是把每次用n来遍历一个节点换成用队列来遍历,这样的话减完以后变成0的节点直接放在队伍后面就可以了,那么实际上就会跑节点数量和边的数量的和!
CODE:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| #include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 1e6+5;
const ll mod = 1e9+7;
string s;
int come[N];
priority_queue<int,vector<int>,greater<int> > q;
vector<int> edge[100],res;
set<int> k;
void solve(){
for(int i=0;i<26;i++)
if(k.count(i) && come[i]==0)
q.push(i);
while(!q.empty()) {
int tmp = q.top();q.pop();
res.push_back(tmp);
for(int i=0;i<edge[tmp].size();i++) {
int x = edge[tmp][i];
come[x]--;
if(come[x]==0 && k.count(x))
q.push(x);
}
}
if(res.size()==k.size()) {
for(int i=0;i<res.size();i++)
putchar(res[i]+'A');
cout<<endl;
}
else
cout<<"No Answer!"<<endl;
}
int main(){
while(cin>>s) {
int x = s[0] - 'A';
int y = s[2] - 'A';
k.insert(x);k.insert(y);
if(s[1]=='>') {
edge[x].push_back(y);
come[y]++;
}
else {
edge[y].push_back(x);
come[x]++;
}
}
solve();
return 0;
}
|
例题2 - 逃生
CODE:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| #include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 1e6+5;
const ll mod = 1e9+7;
priority_queue<int> q;
vector<int>link[N],res;
int come[N];
int n,m,x,y;
void solve() {
for(int i=1;i<=n;i++)
if(come[i]==0)
q.push(i);
while(!q.empty()) {
int tmp = q.top();q.pop();
res.push_back(tmp);
for(int i=0;i<link[tmp].size();i++) {
int v = link[tmp][i];
come[v]--;
if(come[v]==0)
q.push(v);
}
}
for(int i=res.size()-1;i>0;i--)
cout<<res[i]<<" ";
cout<<res[0]<<endl;
}
void init() {
for(int i=1;i<=n;i++) {
link[i].clear();
come[i] = 0;
}
while(!q.empty()) q.pop();
res.clear();
}
int main(){
int _;cin>>_;
while(_--) {
scanf("%d%d",&n,&m);
init();
for(int i=1;i<=m;i++) {
scanf("%d%d",&x,&y);
link[y].push_back(x);
come[x]++;
}
solve();
}
return 0;
}
|
解析:
这个题与众不同的地方就是它采用的排序方式是小数优先?不是很懂,总之这样的排序方式,需要反向建图,然后从后面找最大的放入队列中,因为是反向建图,所以最后也是倒序输出。
6 -> 4 -> 1 ↘
3 -> 9 -> 2 -> 0
5 -> 7 -> 8 ↗
如果图是这样的话,字典序输出肯定就是3 5 6 4 1 7 8 9 2 0
但是我们需要的输出是 6 4 1 3 9 2 5 7 8 0
后面的数一定是大的,那么就倒着取,0,8,7,5,2,9,3,1,4,6。
最后倒序输出,这里是恰好一行一行输出……实际上并不是而是从后往前找大的输出。

 微信
微信 支付宝
支付宝